本文是对原文地址的翻译
word2vec是一个用来处理文本的二层神经网络,它的输入是一个文本集,输出是一系列集合,这个集合是与文本集是对应的。明显word2vec不是一个深度学习网络,它只是将文本转化为深度网络可以理解的数值化格式。
deeplwarning4j实现了一个分布式的Word2vec for Java和Scala,它可以在Spark上运行GPU。
word2vec做的不仅仅是解析文集中的句子,它可以应用于基因,代码,兴趣爱好,私人播放列表,社交媒体图等方面,或者辨别出数据中的抽象化特征(序列)。
这是因为文本也类似于上面提到的数据,有离散的状态,我们只需要找到这些状态中的转化概率,即这些状态可能会重叠的几率。那按照这个逻辑推理,gene2vec,like2vec以及follower2vec这些类似于word2vec的技术也都是可以实现的。有了这些了解,下面就会逐步解释如何为任何一组离散和共现状态创建一个神经嵌入。
(这句话可能翻很生硬,我的理解就是文本中的数据可以看做是离散的数据,这些数据是会有交集的,这种交集可以体现在我说“早上”,那么“好”以及“吃饭了吗”这两个文本与“早上”的关联就会更大一些,那么word2vec要做的就是找到这种文本之间的关联性,按照这种关联性为一个标准,将文本转化为向量)
word2vec的目标就是将相近的词汇汇集在一起,但是不是在文本词汇这个空间,而是在向量这个空间。那么它如何去判断两个词汇是否相近呢?对于人而言可能很简单,对于机器而言就需要建立一个数字化的相似度量机制。
word2vec创建的向量是基于文字特征的分布式数据表示,特征比如说是单个单词的上下文,它会自动完成这些工作不需要人类干涉。
给它充足的数据,语法用意,上下文环境,word2vec可以根据这个单词在其他地方出现方式,高精度的猜测这个单词的意思。这种猜想就可以用来建立一个单词和另一个单词的相似度。就比如说man 和boy,woman和girl,或者将文章根据文章内容的话题来进行分类。这些集群可以构成搜索,情感分析和科学研究,法律发现,电子商务和客户关系管理等多个领域的建议的基础。
The output of the Word2vec neural net is a vocabulary in which each item has a vector attached to it, which can be fed into a deep-learning net or simply queried to detect relationships between words.
word2vec的输出是对应词汇的向量,这些向量可以作为输入传给神经网络,也可以用来研究单词之间的关系。
检测两个单词之间的cosine similarity,如果两个单词之间的相似度为1,是完全重叠的,那么对应的角度为0,两个单词之间对应的角度没有90度,一个单词与另一个单词之间的 cosine distance越大,表明这两个单词的关联越大。(这里特别注意,两个单词之间的关联或者说相似相近度,说的不是单词的拼写,而是它所代表的含义),下面给出一张和Sweden(瑞典)相似度最高的几个单词。
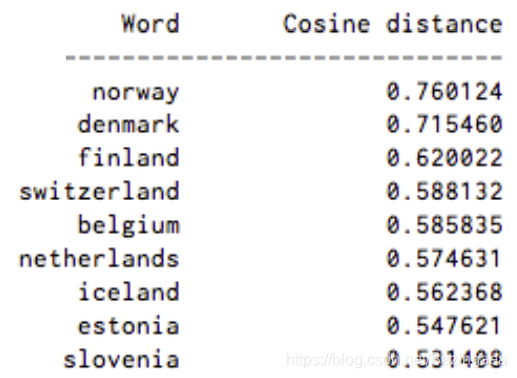
下面要提到另外一个概念,Neural Word Embeddings,翻译为词嵌入,这是自然语言处理(NLP)中语言模型与表征学习技术的统称。
The vectors we use to represent words are called neural word embeddings.
在上文中提到的对应表示单词的向量就叫做neural word embeddings,向量和单词看上去是毫不相关的两个东西,但是通过word2vec可以将单词向量化,这样做的目的就是让计算机能理解自然语言,使得我们能使用强大的数据工具去检测单词之间的相似度。
word2vec就像一个自动编码器,将每个单词编码为向量,但不是以一中重新构造来训练输入单词的方式,而是像限制Boltzmann 机器一样,它训练单词和语料库中和该单词相近的其他单词。
word2vec有两种方式,其一是给出上文猜测下文是什么,这种当时称为CBOW,continuous bag of words,或者是使用一个单词去猜测下文是什么,这种方式称为 skip-gram。我们将使用skip-gram这种方法,因为它会在大量数据上产生更多可观的结果。
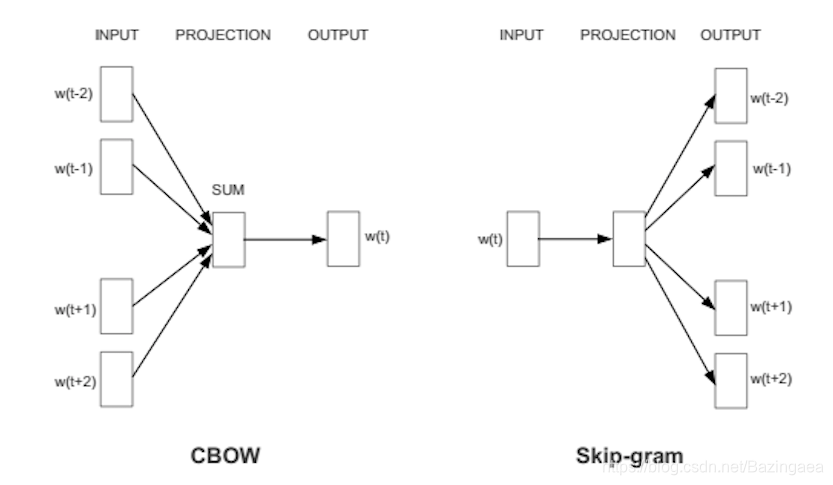
当一个向量被指定给一个单词的时候,并不是说这个向量就可以预测单词的含义了,向量的组成元素还需要不断的调整。按照什么来调整呢?按照文本集中这个单词对应的上下文环境,通过对比来返回一个误差值,然后根据误差值去调整向量值。(这个过程和前反馈神经网络中训练时向前传播和反向传播是一个道理,只是模型的参数变成向量值)
就像梵高用画笔将三维空间里的向日葵绘制到二维空间的画布上一样,一个500维的向量也可以表示一个单词或者单词组。
相似的单词会在训练的过程中集群在一起,(有点类似与多分类问题中,同一分类下的数据也会聚集在一起),一组经过好的训练的单词向量会在向量空间中将相似的单词放在靠近的位置上,就比如橡树,榆树和桦树这两个词可能聚集在一个角落里,而战争,冲突和纷争则挤在另一个角落里。这种单词之间的相似度是word2vec可以学习的东西,而且他可以映射到不同的语言上,如图:
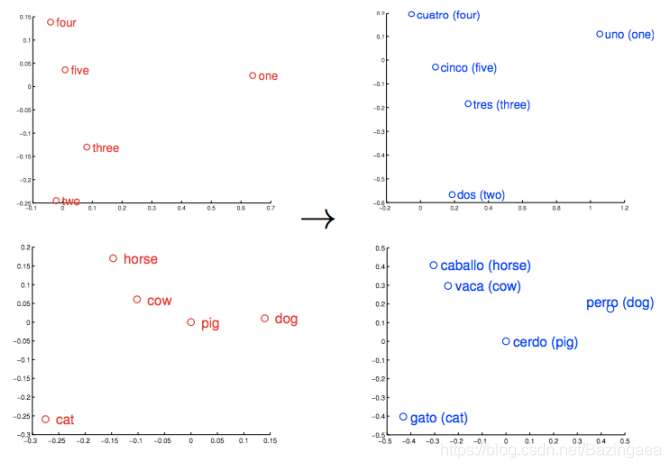
Rome - Italy = Beijing - China. And if you only knew that Rome was the capital of Italy, and were wondering about the capital of China, then the equation Rome -Italy + China would return Beijing. No kidding.
还有一个很有趣的事情,不仅仅是相似单词集群在一起,多层相似关系的单词之间也有联系。比如说 中国和意大利都属于国家,这两个单词是相似的,那么他们会聚集在一起,那北京是中国的首都,罗马是意大利的首都,北京和意大利也会聚集在一起。并且在向量空间上,北京到中国的距离=罗马到意大利的距离。

搞清楚word2vec的输入和训练理念以后,我们来看看它的输出,word2vec会输出一个序列(可以自定义是几个)的单词,这些单词都是和你输入的单词匹配度最高的。下面举几个例子,: 这个符号表示 is to ,::这个符号表示 as
e.g. “Rome is to Italy as Beijing is to China” = Rome:Italy::Beijing:China.
//这个结果有点奇怪 但是好像又是那么回事
king:queen:: man:[woman, Attempted abduction, teenager, girl]
//两个大国的周边城市邻居
China:Taiwan:: Russia:[Ukraine, Moscow, Moldova, Armenia]
上面这个结果对应的模型是基于谷歌的NEWS vocab训练的,在训练之前word2vec这个算法对于英语语法结构一无所知,但是经过训练它就学习了很多内容
It comes to the Google News documents as a blank slate, and by the end of training, it can compute complex analogies that mean something to humans.
它以谷歌新闻文件作为工具,在训练结束时,它可以计算出对人类有意义的复杂类比关系。
出了上面的两种事物进行类别,word2vec还有其他功能,比如:
地缘政治:伊拉克 - 暴力=约旦
区别:人 - 动物=伦理
总统 - 权力=总理
图书馆 - 书籍=霍尔
打个比方:股市≈温度计


